
NewSQL Scalable Relational Databases
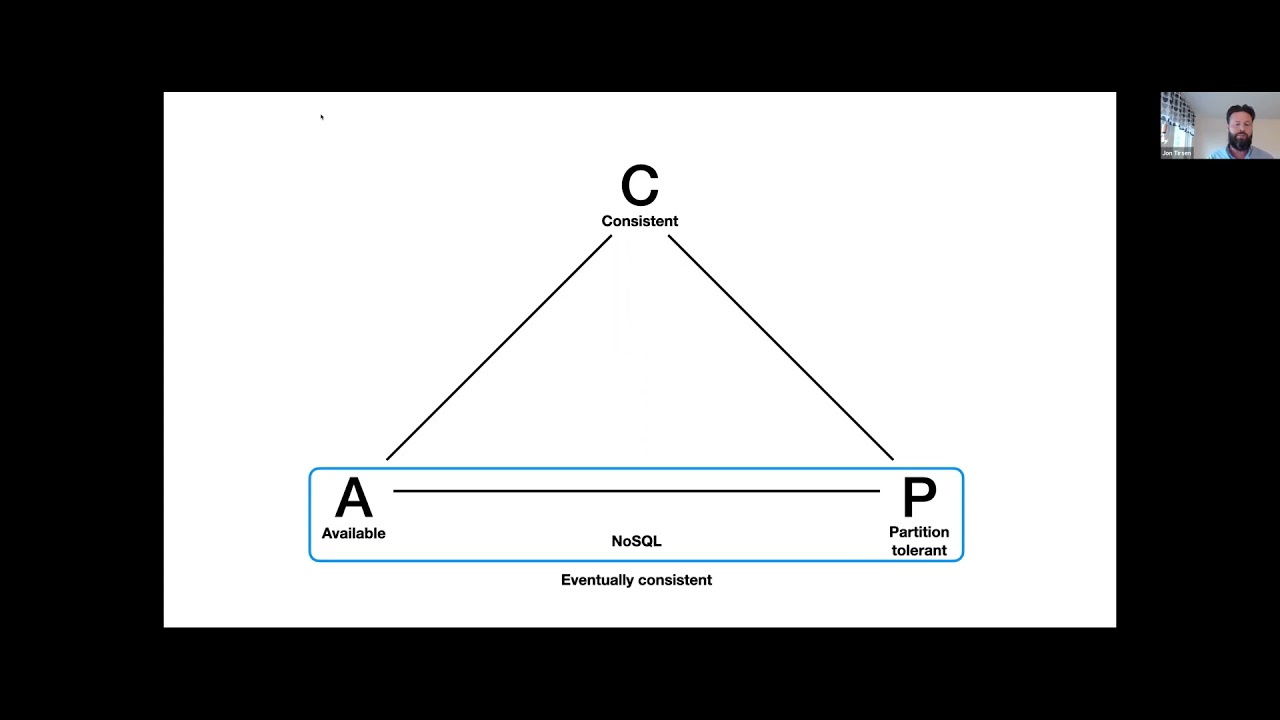
NoSQL was a reaction against the scalability issues with regular SQL relational databases such as MySQL and Postgres. They scaled out well and were easy to operate but were lacking many of the features developers have relied on for decades such as ACID transactions, global indexes and complex queries with …




