Advanced PostgreSQL Schema Design (For Scalable Application Development)
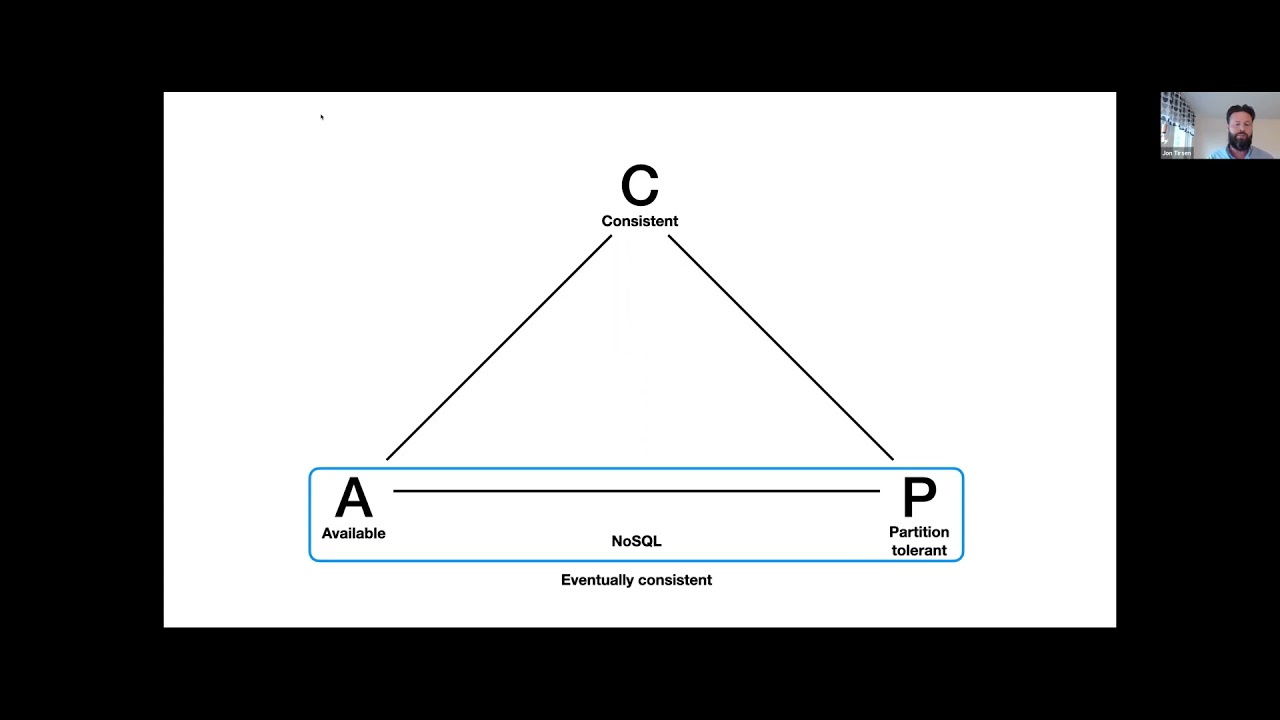
Go beyond CREATE TABLE and CREATE VIEW with functional indexes, exclusion constraints, array types, transactional DDL, and more for simple, scalable application development. This presentation goes into PostgreSQL-specific features that can be leveraged for advanced schema design. The focus will be solving real-world problems faced by application developers to create …