
The MapReduce programming model enables developers without experience with parallel or distributed systems to use the resources of a large system and process big data. Apache Hadoop implements the MapReduce model. The combination of the RDBMS and MapReduce is being researched.
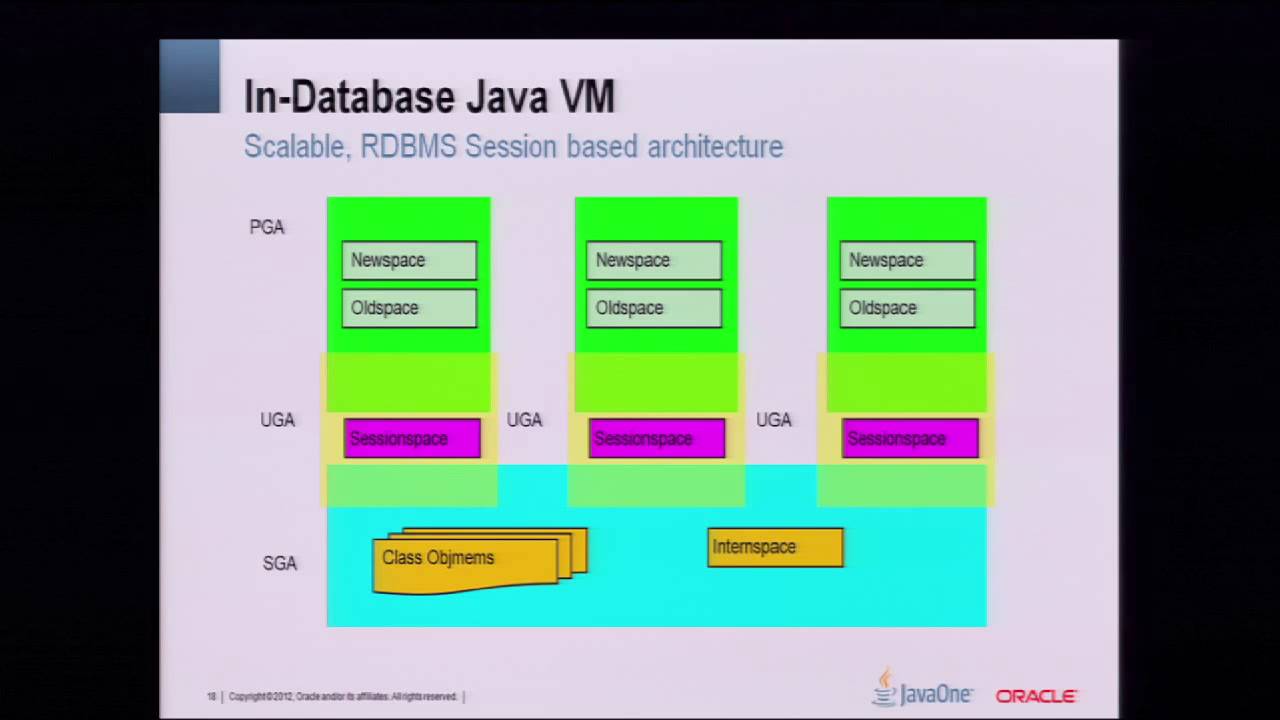
This session describes a prototype of a Hadoop implementation that enables you to reuse native mappers and reducers applications written in Java, directly in the database. Leveraging Java VM in the database is what makes this prototype possible. The major benefits of this implementation: source compatibility with Hadoop, minimal dependency on the Apache Hadoop infrastructure, seamless integration of MapReduce functionality into SQL, and better parallelism and efficiency.
[youtube v3N_sF4TZv0]
Pingback: Why Big Data 101? | Grandiose Data Delusions